On Amazon's EC2, using EBS as the backend storage for your application has been the de-facto standard. Using the local storage of an EC2 container is risky: data loss occurs when a container is stopped and it is not replicated by default. As such, people should default to using EBS, which is Amazon's version of a SAN.
However, at quasardb, we believe that data loss is something that should be expected, not something you have to fight against with expensive hardware:
- replication is synchronous, and as such doesn't return before the write has been processed on all the replicas;
- all writes are OS-level safe, which means that all writes provide as much reliability as the OS provides us with;
- not in a hurry and paranoid? You can even have hardware-level safe writes.
In addition to this, there are a lot of valid reasons to prefer the local instance storage over EBS:
- performance is better: no matter how big your fibre to your SAN is, all other things being equal, local disks are faster;
- there is no single point of failure: several outages on AWS have been EBS-related, which would have been avoided when using instance storage;
- it is cheaper: you don't have to pay an additional monthly fee for SAN storage, and since you are paying for the instance storage anyway, why not use it?
It is worth mentioning that all this highly depends upon the use case of the customer: it is still their choice whether to use instance storage or not, by simply not assigning any instance volumes to the container.
Instance storage comes with a challenge though, when you want to prepare an AMI which you can deploy in any environment: you will have to detect your environment on boot and prepare the filesystem in an automated way. For quasardb we wrote a boot script that does exactly that, and this post guides you through the process of setting up such a script yourself.
Volume management
Amazon's containers provide the instance storages as block volumes: the bigger instances provide multiple instance storage volumes and in an ideal world, we will just access these block devices under a single mount point.
There are two different approaches which may be viable solution to this:
- mdraid, Linux's software raid implementation;
- LVM, is a system of mapping block devices to virtual volumes.
LVM
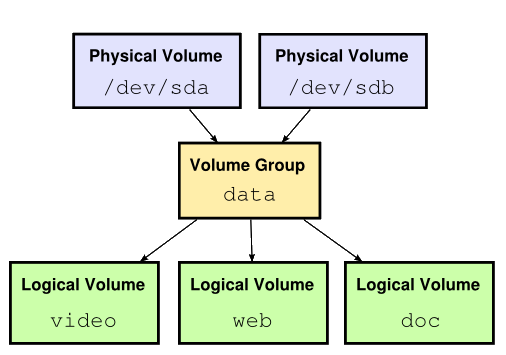
LVM supports striping (LVM-RAID), which actually uses mdraid under the hood. Due to LVM abstracting mdraid away, it is less usefull for the power-user: you cannot us mdadm on it, rebuilding hard disks is a little more troublesome, etc.
However, since we do not want to use multiple devices to recover data, but rather to increase performance, we do not need these features, in which case LVM and mdraid will have (approximately) equal performance. Since LVM is more flexible and user-friendly, we will be using LVM.
LVM allows you to abstract away from raw block devices and present them as virtual block devices (called volumes). You can increase the size of a volume, decrease it, add new disks, remove disks, etcetera.
Detecting existing volumes
The first thing we need to automate is to detect any existing LVM volumes; if someone reboots an EC2 container (for example, after a kernel upgrade) then we do not want to lose any data. We will be detecting existing volumes using lvdisplay:
LVDISPLAY="/sbin/lvdisplay"function detect_volume {
echo $(${LVDISPLAY} | grep 'LV Path' | awk '{print $3}')
}
# Similar to detect_volume, but fails if no volume is found.
function get_volume {
local VOLUME=$(detect_volume)
if [[ -z ${VOLUME} ]]
then
echo "Fatal error: LVM volume not found!" 1>&2
exit 1
fi
echo $VOLUME
}
Using these functions, the functions detectvolume and getvolume will give you the path to the virtual block device LVM provides. The astute reader will notice that this in fact will return multiple LVM volumes when they are available; in my specific use case, this will not be an issue unless our customers start fiddling with LVM configurations themselves.
Detecting block devices
Once we have determined that we do not have an LVM volume yet, we must know which block devices to consider. EC2 containers will have /dev/xvda as the container's root device, which will always be EBS. So, we must find out how many other block devices are available with the same prefix. We can use the bash -b flag to determine whether a path is in fact a block device:
# Detects all local block devices present on the machine, skipping the
# first (which is assumed to be root).
function detect_devices {
local PREFIX=$1
for x in {b..z}
do
DEVICE="${PREFIX}${x}"
if [[ -b ${DEVICE} ]]
then
echo "${DEVICE}"
fi
done
}
This will return a newline-separated string of all block devices we should use to create our LVM volume.
Creating an LVM volume
This step will perform all the most important grunt work: bundle the block devices into a volume group, create a logical volume that uses all the space in that volume group, and creating a filesystem on top of it:
PVCREATE="/sbin/pvcreate"
VGCREATE="/sbin/vgcreate"
LVCREATE="/sbin/lvcreate"MKFS="/sbin/mkfs -t ext4"
# Creates a new LVM volume. Accepts an array of block devices to use as
# physical storage.
function create_volume {
for device in $@
do
${PVCREATE} ${device}
done# Creates a new volume group called 'data' which pools all available block
# devices.
${VGCREATE} data $@# Create a logical volume with all the available storage space assigned
# to it.
${LVCREATE} -l 100%FREE data
# Create a filesystem so we can use the partition.
${MKFS} $(get_volume)
}
At this point, we have an LVM volume with a filesystem created on top of it, and we are able to mount it:
MOUNTPOINT="/mnt/data"
function mount_volume {
echo "mounting: $1 => ${MOUNTPOINT}"
mount $1 ${MOUNTPOINT}
}
Glueing it all together
Now, let's make all this logic work together and combine it in a single script:
# Detect existing LVM volume
VOLUME=$(detect_volume)# And create a brand new LVM volume if none were found
if [[ -z ${VOLUME} ]]
then
create_volume $(detect_devices ${DEVICE_PREFIX})
fi
mount_volume $(get_volume)
Once again, the astute reader will notice that this mounts an LVM volume no matter whether or not this volume was already mounted; this is not a problem, since mount will just throw a warning if it is already mounted.
For completeness' sake, here is the full script:
#!/usr/bin/env bashLVDISPLAY="/sbin/lvdisplay"
PVCREATE="/sbin/pvcreate"
VGCREATE="/sbin/vgcreate"
LVCREATE="/sbin/lvcreate"DEVICE_PREFIX="/dev/xvd"
MKFS="/sbin/mkfs -t ext4"
MOUNTPOINT="/mnt/data"function mount_volume {
echo "mounting: $1 => ${MOUNTPOINT}"
mount $1 ${MOUNTPOINT}
}# Detects all local block devices present on the machine, skipping the
# first (which is assumed to be root).
function detect_devices {
local PREFIX=$1
for x in {b..z}
do
DEVICE="${PREFIX}${x}"
if [[ -b ${DEVICE} ]]
then
echo "${DEVICE}"
fi
done
}# Creates a new LVM volume. Accepts an array of block devices to use as
# physical storage.
function create_volume {
for device in $@
do
${PVCREATE} ${device}
done# Creates a new volume group called 'data' which pools all available block
# devices.
${VGCREATE} data $@# Create a logical volume with all the available storage space assigned
# to it.
${LVCREATE} -l 100%FREE data# Create a filesystem so we can use the partition.
${MKFS} $(get_volume)
}function detect_volume {
echo $(${LVDISPLAY} | grep 'LV Path' | awk '{print $3}')
}# Similar to detect_volume, but fails if no volume is found.
function get_volume {
local VOLUME=$(detect_volume)
if [[ -z ${VOLUME} ]]
then
echo "Fatal error: LVM volume not found!" 1>&2
exit 1
fi
echo $VOLUME
}# Detect existing LVM volume
VOLUME=$(detect_volume)# And create a brand new LVM volume if none were found
if [[ -z ${VOLUME} ]]
then
create_volume $(detect_devices ${DEVICE_PREFIX})
fi
mount_volume $(get_volume)
We believe that in this way, we can get the best performance and reliability out of AWS, in addition to providing the customer with the freedom to choose between EBS and instance storage themselves.
What are you thoughts?