Introduction
Industrial Internet of Things (IIoT) is facing the new challenge of having to ingest very high volume of timeseries data and perform complex analysis in real time.
Doing one of the two is hard, the two at the same time is extremely challenging. In other words, you want to have your cake, eat it, own the bakery, and paying yourself massive dividends every year.
Quasardb was built on the vision where we can make the world more efficient if we instrument everything, at the highest possible resolution, and use that data to make decisions. This is applying the logic of a quantitative hedge fund (who happen to be another big vertical for us) to the industrial world.
The first part of the plan was to build the database engine capable of processing the new volume of data while delivering complex analytics.
In 2020, we have started phase two of our plan where we integrate the database in the industrial apparatus.
This blog post is about the lessons we’ve learned along the way.
Timeseries in Industrial IoT
Monitoring
When you build monitoring for your industrial application, you can get away with one point per second (and sometimes even less) per sensor. Even if you have hundreds of thousands of sensors, that's still less than a million points per second, often below a megabyte per second of new data.
Additionally, monitoring rarely requiress a high-resolution history, meaning that you can reduce the resolution to one point per minute (or even less), making it possible to fit a multi-year history in less than a gigabyte.
That's because if you're interested in "when a failure happened," you don't need to know at the microsecond.
Predictive maintenance
Monitoring is a must, but monitoring is reacting when you should be anticipating. What you want to do is to know when a problem will happen before it happens: that's predictive maintenance. To do that, you build models on finely grained data. Once your model is ready, you then inject all that raw data in real-time and process alerts.
How does it work? You're looking for something called "weak signals." A weak signal can be, for example, a specific spike of electric consumption, which in itself isn't a problem, but, after analyzing years of historical data, you know this spike (or series of spikes) is heavily correlated, with, for example, a turbine failure.
The higher the resolution, the better because the difference between a non-event and the prelude to a problem can be very subtle. It is as if you were trying to make sense of a green spot on a low-resolution picture. Is it a tree, an animal, a person?
Another class of problem
Old-school monitoring applications don't impose a particular challenge on databases unless you are at an enormous scale. When you have data with second-granularity, a case could be made that you maybe don't even need a timeseries database, except for convenience, efficiency, or because you're doing specific queries that TSDBs are very good at (such as ASOF joins).
However, serious predictive maintenance is another story. Sensors typically sample at 2-4 kHz, which means you have 2,000 to 4,000 times more data than before. Some customers are even beyond 20 kHz, that is 20,000 times more data than second-granularity!
Gigabytes become terabytes; terabytes become petabytes.
You could downsample. But will you make up what the green spot on the image is?
As an example, we'll focus on electrical waveform data to discuss the specific challenges of doing data science on the full raw stream of data.
What do we mean by electrical waveform data?
Electrical waveform data represents the variation of electricity amperage (I) and voltage (U) over time.
If you see electricity as a stream of water, amperage is the strength of the current, and voltage is the difference in height between two points.
The electricity you have at home is called two-wire single-phase electric power, with a third conductor called the ground to prevent electric shock. The current alternates, meaning the voltage varies over time at a fixed frequency (usually 50 Hz or 60 Hz). If you wanted to monitor an electric outlet at home, you would thus have two values at any point in time.
However, in industrial applications, three-wire three-phase electric power is the norm, mostly because it enables you to transmit the same amount of electrical power with less conductor material. This means that for every point, you don't have just two values (I and U), but six (I1, U1, I2, U2, I3, U3). Oops! Suddenly, three times more data!
A problem of scale
But, wait, there's more!
We have observed that data within machinery is often sampled between 1 kHz and 5 kHz; you can represent each point using fixed-point notation or floating-point notation data. The sensor's bit depth is usually around 16-bit, meaning a double-precision floating-point (64-bit) will have no loss of precision, and floating-point is often easier to work with for data scientists.
If you include a nanosecond precise timestamp, every sample is 6 floating-point values and 1 high-resolution timestamp. Because life is never simple, every sample comes with labels in strings embedding necessary metadata. No, you can't get rid of the labels, unless you really want the data science team to be unhappy!
Long stories short, you quickly end up with tens, if not hundreds, of megabytes of raw data per second to store in your database.
How did our users solve the problem?
Prior to using QuasarDB, customers would typically use one of the following approaches:
- Give up and working on raw data and downsample it until it fits in the system.
- Store the waveform data in blocks of x seconds in blob storage and resort to convoluted scripts to inject that data into data science tools. This can record the data at the required speed, but at the cost at very high querying complexity (and forget about those fancy ASOF joins!). It can also create impedance problems with the data science tools that need to load more data than required.
- Use a data warehousing solution such as Redshift, Big Query, or Snowflake. That works for a while until the data scientist team realizes that queries remain very slow even with an infinite amount of money, and the CFO shows up at the office with an explosive vest. That's because data warehousing solutions are not optimized for write-heavy scenarios. No free lunch! All these indexes are expensive to maintain.
- Use Hadoop and… no just kidding.
If you work in finance, the above may remind you of the dilemma of working with Level II Market Data.
How we solve the problem
We think the good solution enables ingestion at least one order of magnitude faster than the data arrives (to enable restoring from backups in a reasonable amount of time), while enabling transparent querying so that the data science team can pick and zoom on any part of the history at any time.
On top of that, you want storage to be cost efficient through compression.
To do that, we store raw waveforms as timeseries data inside QuasarDB. These waveform can be queried through a SQL-like language or retrieved at very high-speed using a low-level API, when needed.
How we typically model the waveform
Flexible representation
The typical approach in data warehousing is to store all the data in a couple of large tables and pray the underlying implementation will sort it out. It almost works until you write hundreds of millions of points per second to a table, and the SSD starts to generate a black hole under the data pressure.
Fortunately, a quasar isn't a black hole.
The most efficient and convenient way to store waveforms in QuasarDB is to store each sensor as a separate timeseries. It's convenient because you can align waveforms to each other using ASOF joins or downsample them on the fly. You can also easily visualize them for any arbitrary time range without worrying about the underlying representation.
You may ask, but then, how can I query a group of sensors? We have a solution for that: table tagging.
Let's imagine we have two sensors for three-phase electrical data, in two separate tables, stored as such:
CREATE TABLE sensor1 (phase1 double, phase2 double, phase3 double)
CREATE TABLE sensor2 (phase1 double, phase2 double, phase3 double)
You can group these two tables by attaching a tag "machine_a" to both of them and then write the following query
SELECT * FROM FIND(tag=’machine_a’)
Which will be the equivalent of
SELECT * FROM sensor1, sensor2
Since tags can be added, changed, and removed instantly, this creates a very flexible meta-model and doesn't force too many decisions early in the project. Adding a sensor is just adding a table. A single table can have thousands of tags, and tags can be tagged to allow for recursive queries (more on this in the doc).
Ok, now, I can hear you say, "but how will I write to thousands of tables at the same time?!". Luckily, we also have a solution: our batch writer supports multi-table writes and optimizes the exchanges with the database. Using the batch writer, one of our customers commits to 250,000 tables every minute on a cluster made of only two AWS m5.8xlarge nodes.
If you're interested in learning more about writing efficiently to Quasardb, this blog post may be of interest.
Efficient encoding
While QuasarDB delivers raw power, you can go even further by being smart about how you represent the data.
To achieve maximum performance, the first thing we do is leverage the symbol tables of QuasarDB to minimize the size of the strings at every row. A symbol table is a big dictionary that will associate an integer to a string value and is a great choice when strings' cardinality is low. Symbol tables are dynamic so you don't have to know every possible string representation in advance, and they can hold billions of symbols efficiently.
Symbol tables are more efficient for two reasons. First, encoding an integer is smaller than a string as soon as the string exceeds 8 characters. Even when that's not the case, our Delta4C technology can then compress that data very efficiently, much better than if it were the same strings.
For convenience, we often use floating-point columns to store the sensor value. QuasarDB has double-precision floating points, and the bit-depth of sensors is usually 16-bit. In theory, that means we waste 48-bit of space per column, but again, Delta 4C can detect the actual entropy and store that data efficiently. It's much more comfortable for the data scientist to query the data and get floating-point out of the box.
From the machine in the plant to the dashboard in the office
Now that we know how we will store the data, how do we get it into the cluster? The data collection is often already in place at the factory level and done by historians who push the data to the cloud via MQTT. This is the most frequent setup that we've seen.
Once the data arrives in the cloud there are two main possibilities
- Directly write the data from MQTT into Quasardb
- Write the data from MQTT to an event stream processor such as Kafka or Kinesis, and then use the Quasardb connector
Option 1 has less latency and potentially more performance, but option 2 enables you to replay data and do a last-minute triage before inserting data into the database.
Stream processors can also record the streams, which is very useful to track down any data incoherence issues between the source (sensors) and the database. That also simplifies maintenance operation on the database as you can buffer writes for a while.
For these reasons, unless there's a strict latency requirement, we recommend adding a stream processor between the MQTT incoming data and the database cluster.
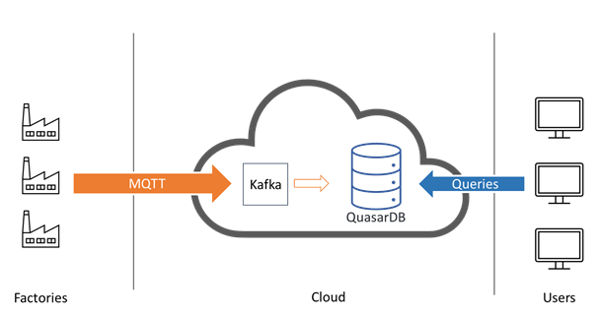
Once the data is in the cluster, the final consumer needs to connect to it, either directly, for example in the case of a Python program (where it would use the high-performance Python API) or indirectly via an ODBC driver for users working with Microsoft Excel, Tableau, and SAS Viya.
This connectivity has no intrinsic complexity as our API takes care of all the nasty details related to having a client talk to a cluster (and not a single instance).
The safest way to do that is to give these users read-only accounts to prevent accidental data modifications (further restrictions can be applied, for example, if not all users should see all the data).
Historical data management
Working with the data format
In every project we've been involved in, there's usually a multi-month (sometimes multi-year) archive of historical data that we want to have in QuasarDB; that way, data scientists will have more freedom to explore and test their models.
We've seen three forms of data:
- Parquet files
- CSV/TSV files
- Json files
Parquet files are the best to work with because their columnar nature enables Railgun, our importing tool, to work at full speed. There is also less ambiguity about the data because it's a self-described format. However, sometimes, the way the information is put in the parquet file is incorrect. For example, numbers can be stored as strings, which means there's extra work in analyzing the data. Timestamps can also be recorded as strings or be broken up into several columns.
The other problem is that when parquet files are not ordered by time. When doing massive imports, it makes an enormous difference if you can import the data chronologically for a given timeseries because QuasarDB has several optimizations to take advantage of it.
We've found it's much faster to sort all files and then load them using Railgun that loading each file unsorted, and the larger the history, the more critical this preprocessing is.
CSV/TSV files are natively supported by Railgun and require some extra validation regarding the data format; speed is lower than with parquet files but can still be good enough to saturate your network bandwidth.
Lastly, JSON files are our least favorite data format. It often requires bespoke scripting and decoding. Reencoding is the slowest of these three formats, and representation is the least compact.
We recommend that you store the data in compressed parquet files with carefully chosen column types for archival needs.
Massive import
To import the data, we always proceed in that way
- Pick random files in the archive and attempt to import them with Railgun straight away. 90% of the time, this goes well, and we can script Railgun to import the whole history.
- If files have an incorrect/incoherent data format, some extra clean-up phase is needed. It can either be a script that prepares the file before sending it to Railgun, or, in the most extreme case, we must write a custom data loader that will leverage QuasarDB batch API.
- If the files are not sorted by time, it's worth spending the time to sort them. The larger the data set, the more the difference it makes. This problem doesn't exist for real-time streams because real-time streams are never as big as massive batch loads.
Querying the data
By querying the data, we mean, yes, the act of writing a query, but not just that.
When building a high-performance data system, it's easy to lose track of what is important: ensuring the user can solve the business problem.
When working with waveform data, there are three things:
- Visualize waveform data
- Building a model, means loading chunks of the waveform to enable data scientists to find patterns
- Feeding data to a model on a subset of sensors to detect anomalies in real-time
For 1, it can be a SELECT *, or a SELECT avg(val) GROUP BY minute (or any other time interval) to downsample the data (visualization software may suffocate on the full stream of raw data), or a SELECT quadratic_mean(val) GROUP BY minute since the root mean square of alternating current is the the value of the direct current for the interval considered (and we have a SIMD accelerated RMS function named quadratic_mean).
For 2, that's the raw data, but often aligned between two or more sensors, sometimes pivoted. That means a SELECT * from sensor1 LEFT ASOF JOIN sensor2 with maybe a PIVOT criteria at the end. You want to align two sensors to feed the model because the timestamps won't be perfectly identical; from the point of view of building the model, you may want, for example, electrical waveform to be perfectly aligned with pressure data.
3 is running the same queries as in 2, but feeding that to a monitoring or alerting platform.
Sensible storage management
If you go back to our initial discussion, you quickly realize that while QuasarDB may ingest that data, storing it in the cloud can become challenging.
The Delta4C will do an excellent job at keeping data as tight as possible on the disk, but inevitably, there will be a point when you get close to a petabyte of storage, and that's when you need to start some forward-thinking.
We have also observed that whatever gain compression gives is compensated by our customer's appetite for MORE HISTORY. Like the law of perfect gazes, every available byte of storage ends up being used.
If you're an AWS customer and want to keep an extensive history within QuasarDB you may wish to leverage our "S3 as a backend" extension that uses the technology from our friends at Rockset. Storing data in S3 makes a petabyte timeseries cloud solution realistic in terms of cost. I know Jeff needs to redo the helipad on his yacht, but that will have to wait.
When you run QuasarDB on-premises, we typically leverage our tiered storage configuration to optimize cost and performance. Complete data scans are rare and older data tends to be queried less often, making it possible to keep the more recent data faster, but more expensive, storage, and migrate aging data away.
More information
Whether or not you're considering QuasarDB for your next project, we hope you found the information in this article useful and actionable. If that made you curious about Quasardb, give our free community edition a try, it's free of charge and fully featured!