This port is the first in a series about the challenges behind database performance and how to accurately assess it. In future posts, we will dig more into the specifics of benchmarks and design choices.
The Penrose stairs of performance
If you are following database innovation you can see that nearly every database vendor out there has at least one benchmark putting them in the first place. With every vendor selling the fastest database there is, you end up in a Penrose stairs situation where everyone is faster than everyone.
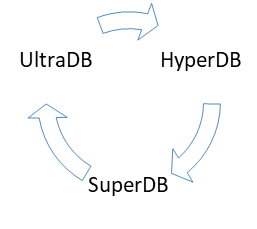
The above isn’t always that obvious as not all benchmarks include the whole competition. Let’s say UltraDB publishes a benchmark where they show they are 2X faster than HyperDB, who previously said than they are 2X faster than SuperDB. Then SuperDB announces they are 2X faster than UltraDB.
\begin{cases} x = perf(UltraDB)\\ y = perf(HyperDB)\\ z = perf(SuperDB)\\ x = 2y\\ y = 2z\\ z = 2x\\ \end{cases}
The mathematician in you may sarcastically note that it’s possible if the performance level of all databases is 0.
That’s why we’ve always been prudent with benchmarks at QuasarDB as most of them are completely useless and don’t measure anything pertaining to real use cases.
“For every database, it is possible to conceive at least one benchmark that will place it well ahead of the rest.”
Nevertheless, the question “Could you tell us how you measure compared to the competition, in a concise way?” is not only reasonable but absolutely on point.
What is performance?
One way you can get away with some crazy claims is the vagueness of the word performance. Is it latency? Is it how much RAM you use? Is it how much disk you use? Is it how fast an aggregation is? How fast insertion is?
We can start with what performance is not: it’s not a number. Yes, sorry, it’s not something you can measure in megabytes per second summarizing the whole capability of a product.
Performance is, how efficiently the product will handle the workload you submit to it. When you are assessing a database performance, you must then be sure about what your needs are.
Is it insertion speed? Aggregation speed? If yes, what kind of aggregation? What type of data do you expect to mostly process?
These questions may sound overwhelming, but they really are not, and you already have the answers!
As an example, here is the list of information one of our solutions architect will typically ask before a PoC (keep in mind these questions are timeseries oriented), and some possible answers:
- What is your data ingestion rate?
- We ingest 10 GiB of new data per day with a peak of 100 MiB/s in the morning.
- We have a peak of 100 million updates per second, an update being a timestamp and a floating-point number.
- For how long do you need to keep the data?
- We need to keep the data for one week.
- We need to keep the data for 7 years; however, we rarely query beyond one month ago.
- What is the most prominent data type?
- It’s mostly integers.
- We have a mixture of strings and floating-point numbers.
- What maximum latency can you accept for an update to be visible?
- The lower the better.
- We only refresh our indexes every hour, our requirements are thus not strict.
- What is your most frequent query?
- Raw data query (i.e. get the data between two points in time).
- A moving average of the price weighted by volume.
It’s acceptable to answer “I don’t know” to any of these questions, you just need a way to be able to figure out an answer within one order of magnitude.
Do you care about performance?
It happens sometimes that during a meeting with a prospect that our sales team gets the “We don’t care about performance” statement.
This is of course untrue as I have yet to meet someone who would not be happy with a system going faster, or unhappy with a system going slower. What it means is that more performance may not bring significant value to the business or that it’s not the problem the customer is currently trying to solve.
However, what can be interesting to think about is the what if. What if my database could do 10X more? 100X more? Would that enable me to do things I could not do before? Could that help me grow my business?
On one hand, the biggest advantage of performance is how much headroom and flexibility it gives you. If that additional performance doesn’t come with any significant drawback, most of the time, you should take it.
On the other hand, selecting a database purely on its performance merits is always a wrong decision. Performance for the sake of performance is totally useless, and that’s also why trying to desperately come up as the fastest database in a benchmark may be good for the ego but does not necessarily translate to satisfied customers.
The right approach, for us, is to define your workload and the service level you need, and, to ensure that the product you are evaluating can, not only deliver steadily, but has enough margin so that you don’t run into problems quickly.
For example, if you need to refresh a dashboard every minute, you need your database to be able to deliver the updates an order of magnitude faster than that.
Understanding performance
About database design
To understand database performance, there is something important to be understood about database design.
When designing a database, you must make certain number of choices that will impact how well the product will behave depending on the workload. You cannot have it all, it is just impossible.
For example, QuasarDB is column-oriented. This mean, data is arranged in columns, not in rows. That makes aggregations on the data of the same column faster, because, in part, of the way CPU caches work. However, aggregations on rows will be slower as you will have to traverse different data structures for each row.
You cannot be row oriented and column oriented, unless you duplicate all data (in which case you sacrifice disk and memory usage). As a database designer, you must make a choice.
Is it bad? Is it good? It depends on the workload. Since QuasarDB is optimized for timeseries, column oriented was a natural choice, not only for aggregation speed, but also, for storage efficiency needs as compressing a timeseries column is more efficient than compressing a row.
This is just one example among the hundred of decisions that goes into designing a database, and the sum of all these decisions will determine the performance profile of the final product.
Is it cheating?
All databases operate in the same physical realm. If one database is performing significantly better than the others, it is likely doing something differently or sometimes not doing anything at all.
By not doing anything at all, we mean that it can be precomputed/cached results, or not actually writing to disk (delayed writes). It’s very important to find that out as depending on your workload, this can matter or not.
When evaluating products, it’s thus important to understand the why. Is it because of the way the database is designed or some unique innovations? Or is it just because the database is kind of “cheating” the test?
If you’re reading a marketing brochure or seeing a PowerPoint, usually the technical details about the benchmark aren’t present, simply because, well, there is no room for it.
If you’re reading a detailed performance report, the method of the benchmark should be described, and ideally how the databases have been configured. The best performance reports will not only show the results but explain them with an error margin. For example, “We conjecture that SuperDB has a faster insertion speed because it uses an LSM tree structure whereas UltraDB has a BTree structure”.
To summarize, if you see a huge difference and there is no tangible explanation, you should dig more. In future blog posts we will give concrete example of how you can make a benchmark say whatever you want it to say.
The never-ending work on performance improvements
That brings me to our answer when we get asked “Why are you guys so fast?”.
While I would like to be able to point out to some specific things that make QuasarDB that fast, it’s not that simple.
There are some architectural decisions that plays in our favor (the way we serialize data, how we arrange it in memory, kernel bypasses, custom compression algorithms…), but if I had to point one factor it’s because we just measure everything all the time.
This goes from micro and macro-benchmarks in the continuous integration to profiling the code on a regular basis to ensure all bottlenecks are identified and corrected.
One good example of that process is what happened recently for the forthcoming 3.2 release.
We introduced recently a way to optimize timestamp storage across different columns, for storage efficiency purposes. That showed appreciable gains in terms of disk usage however our QA team quickly picked up that querying speed was significantly worse (20% loss).
It didn’t make any sense as this optimization didn’t touch the query code… Or did it?
What profiling showed is that some essential data structure was read and deserialized from disk on every access, even if the data was already in memory. It was done for simplicity sake assuming that since the amount of data is small (a couple of bytes), it shouldn’t have any impact.
QA proved the developer wrong! The fix was trivial, and performance was back to normal.
Given the complexity of a distributed database, if you don’t catch regressions as soon as they appear, over the years you end with a product that is the fraction of what it originally was.
True performance is a process of constant improvement and is highly correlated to software quality.
Takeaways
What can we remember?
- Be critical of benchmarks.
- Understanding your workload will help you read performance reports better.
- Performance always matters, the question is, how much of it you need and how much value it brings.
- Numbers need to make sense. Huge differences need explanations.
- Performance is a constant battle: keeping a product fast is significantly harder than making it fast.
Curious about QuasarDB? Give our free community edition a try!